

What if you could build software once and run it (almost) anywhere? Whether on a bare metal server, a virtual machine, or in a container?
What if you could move a legacy application into the cloud without rewriting it?
What if you could empower your applications to recover from failure on their own – without the need for a central coordinator?
I have news for you, you can do all these things today with Habitat.
Habitat is Application Automation – we’ll go deeper into what that means in just a moment.
Before we cover exactly what Habitat is, we first need to discuss the why of Habitat.
Why Habitat?
The reason Habitat was created is simple – building and running software is painful! It’s tied to particular runtimes and environments. You need one runtime for a Ruby application and another for a Java application. You need different packages for different operating systems – i.e. one for a Debian system and another for a Red Hat system. Additionally, you need different packages for running on bare metal or in a virtual machine vs. in a container.
Habitat alleviates this pain by transforming applications – including existing legacy applications – into modern applications.
Modern Applications
A modern application
- is immutable
- is agnostic to running environment
- reduces complexity
- enables scaling
Building a modern application looks like this:

It starts with storing all code – both the application code and automation code – in a source code repository. You then use that code to built an artifact or software package. That package is then sent to an artifact repository. This repository is where you can store software artifacts, find other artifacts, and download those artifacts. Those artifacts are then pulled to and deployed to a bare metal server, a virtual machine, or a container without needing to change the artifact. The point of this artifact is that it should be able to run anywhere. Habitat was designed with this workflow at the forefront. If you are familiar with the 12 Factor App, that is exactly the workflow we are embracing.
This is the why of Habitat. Now that we’ve covered the why…
What is Habitat?
Let’s cover what exactly Habitat is.
Briefly, Habitat is a new technology to build, deploy, and manage applications in any environment from traditional datacenters to containerized microservices.
The reason for this is, in Habitat, the application is the unit of automation. This means the application package contains everything needed to deploy, run, and maintain the application.
How does it work?
Let’s first cover packaging an application with Habitat.
Packaging an Application with Habitat
Creating an application with Habitat starts with the user. This is you at your workstation – it can be a Windows, Mac, or Linux workstation, you can create Habitat packages on all of them. On that workstation, you create a plan. This contains instructions on how the application should be set up wherever it is deployed. When you are creating a package for a Linux system, you would write this plan in bash. If it’s for a Windows system you would write that in PowerShell. (NOTE – The PowerShell functionality is still in development at this time, though there will be a video demonstrating this later in this blog post). Then, you use that plan and the compiled application code to create an artifact that contains everything in one place. That artifact is cryptographically signed with a key so you can verify that the artifact came from the place you expected it to come from. We also use this key when we run the application. And then, you can optionally upload that artifact to the public Habitat depot – where you can find Habitat packages by developers all over the world.
Now, once we’ve made the application, we then need to run the application.
Running the Application with Habitat
If the application package is on the depot, you would find it on the depot. Then, pull that artifact from that depot onto wherever you run it – whether bare metal server, virtual machine, or container. If you are not using the depot, you can also upload it to wherever you want to run it through scp or whatever method you prefer. You then use Habitat to start and run that package. We’ll go deeper into that in just a bit.

Once you have that application running somewhere – in this picture it’s a virtual machine – with the supervisor, you can still get information in and out of the application through a restful API.

The real magic of the supervisor comes when you have more than one instance of an application running – let’s say we have four virtual machines all running the same package.
The supervisors on each of these virtual machines form a ring. They will use that key we used to sign the package to decide whether to allow another virtual machine into the ring. They all have to be signed with the same key in order to communicate with each other. They do this communication over an encrypted GOSSIP protocol which they can then use to self organize into different topologies – we’ll cover those topologies a little later.
Habitat Components
Habitat has several parts – some of which are still in development. When I last spoke to Jamie Winsor – one of the creators of Habitat – he described it as an umbrella over many components, all designed to allow you to build software once and run it anywhere. Although the components in development are very promising, the point of this post is to highlight what you can do with Habitat today.
Today, you can create and run application packages that can run (nearly) anywhere, move existing applications into the cloud, and give your applications the intelligence to recover from failure on their own, without the need for central supervisor or controller.
I want us to understand what we can do with Habitat today and then together – since Habitat is fully open source and this project will largely be driven by our community and contributors – we can shape where it goes in the future.
Habitat Supervisor
Let’s start with the Habitat Supervisor – this is what runs the application artifact. The Supervisor is what allows you to run the artifact natively on hardware, in a virtual machine, or in a container (in the case of a container, you can also run it through a container orchestration service like Kubernetes, Mesosphere, or Docker Swarm).
Process Manager
One of the main duties of the Habitat Supervisor is to act as a process manager. This means it starts up and monitors the software within the artifact package (regardless of what infrastructure you run it on).
Additionally, it will also receive and implement configuration changes. So if a new version of a package becomes available – say for a security patch – the supervisor will install it and make whatever configuration changes needed for it. And it also runs services.
Service
A service is one habitat package running under a supervisor. The simplest example is one supervisor running one service on one piece of infrastructure – whether a bare metal server, virtual machine, or container.
Let’s look at an example of this – this video shows a Linux virtual machine running Microsoft Azure. Once the package is on the virtual machine (whether through pulling from the depot or uploading it through scp or ftp), all that is needed to start it is to run the <code>$ hab start</code> command. Once it’s started, if I head to that virtual machine’s IP address in a web browser, the software within that package will be running.
The example in the above video is one supervisor running one service. But one service is pretty limiting. Once we go beyond one service, we need a supervisor ring.
Supervisor Ring
And let’s look at an example of this. Let’s say we start off with one supervisor on a virtual machine running MySQL.
And we decide we want a MySQL cluster, so we spin up two more virtual machines and install the MySQL habitat package on them. Since that MySQL package on each of them is signed with the same key, they will be allowed to form a supervisor ring.
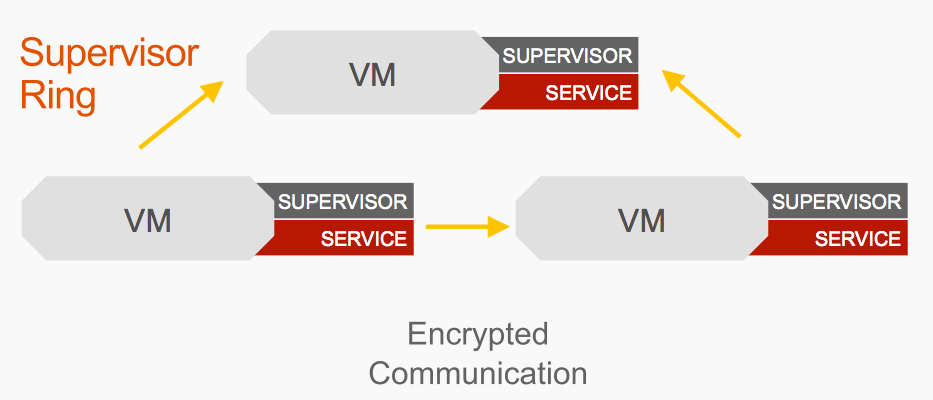
And we decide we want a MySQL cluster, so we spin up two more Virtual Machines and install the MySQL hart package on them. Since that MySQL package on each of them is signed with the same key, they will be allowed to form a supervisor ring. What the ring allows these virtual machines to do is to communicate over each other over a GOSSIP protocol – remember, that communication is all encrypted.
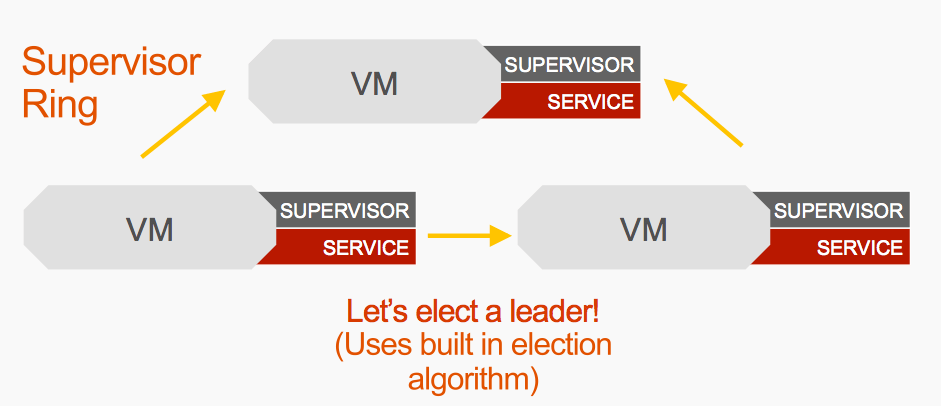
With a MySql cluster like this, it’s common to use a leader/follower topology. What this means is once we have those three virtual machines running that MySQL service, they need to elect a leader. Habitat has a built in algorithm for electing a leader in a cluster such as this. And it’s going to run that election algorithm…
And let’s say this one on the top is elected the leader, that means it will receive the write requests which come to this MySQL cluster. That means the other two virtual machines are designated as followers, and they receive the read requests that come into that cluster.
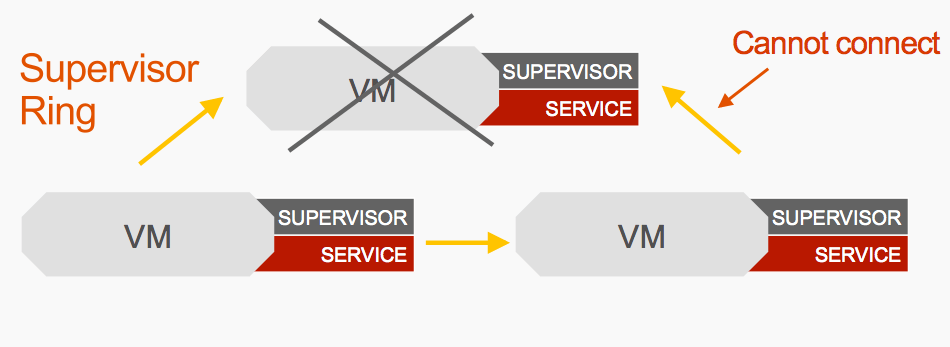
Now let’s say something goes wrong. Something bad happens and the leader goes offline. The two other Supervisors will notice this when they cannot connect with the leader over that GOSSIP protocol.
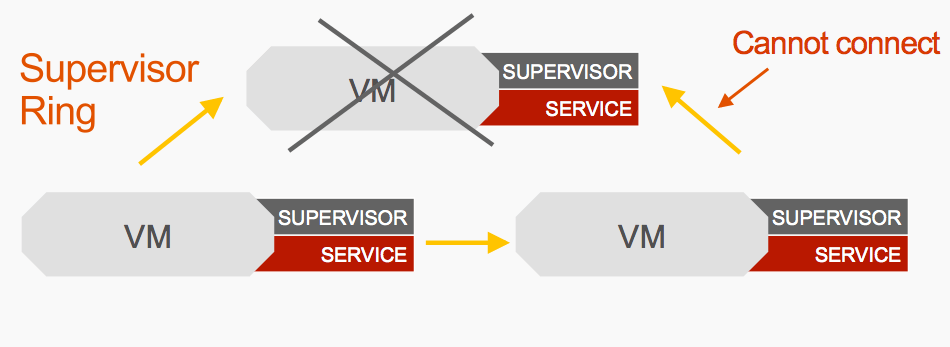
And they will take it out of that supervisor ring. So now we are down to two VMs, and at the moment both are still followers.
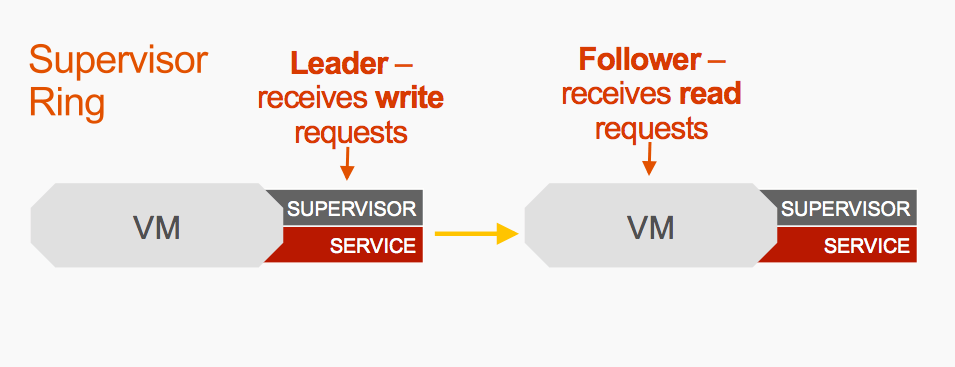
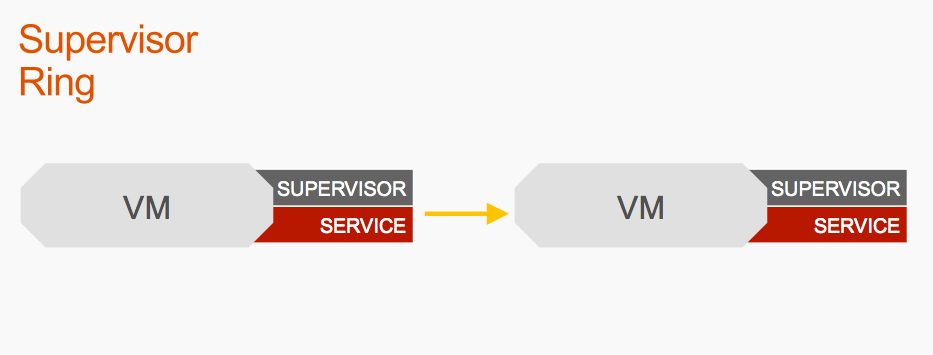
Let’s say this supervisor wins the election and becomes the leader. It will automatically start receiving write requests. And that means this supervisor would be the follower and receive read requests.
This illustrates that Habitat assumes that failures will happen and that they are normal. We don’t try to anticipate every edge case in the beginning because, frankly, we can’t. There will always be something unforeseen that happens somewhere in an application’s lifecycle.
The remaining healthy components will self-organize and re-converge on their own. There’s no central coordinate that re-organizes and re-converges them, they have the intelligence to do this on their own.
Supervisor Topologies
The Habitat Supervisor supports two different topologies at this time. We just saw this first one – Leader/Follower. And the other topology is the Standalone topology – which assumes that every member of the supervisor ring is working as an individual that is in communication with all the others. These are based on existing standards for IT infrastructure.
Handling Package Updates
When a new package becomes available, Habitat deploys it according to an update strategy. The only strategy currently supported is All at Once. That’s when – whenever a new package becomes available – all the supervisors update to that new package immediately. The other that will soon be supported is Rollout. That means if we have a supervisor ring with, say, four supervisors – one will update, then the next one will update, then the next one. Only one supervisor will be updating at any given time.
That’s the Supervisor, which is used to supervise and managed applications packaged with Habitat. Let’s now step back a bit and talk about how we make that package for the Supervisor to supervise.
Habitat Packaging Format
Habitat packages are in a format called the HART format – because we heart you. That stands for Habitat Artifact.
And these HART packages contain the compiled application itself – if for example you had a Java application you were automating, you would have the compiled Java application within this package. Along with the application, these packages also include everything needed to deploy and run the application. This is all kept in one place.
Let’s take a look at how we would create and build this package:
As we just saw, Habitat plans use Bash for packages that will run on Linux. Habitat can also create plans in PowerShell for installing on Windows infrastructure. This is still in the development stages, but here is a preview.
Along with creating and running HART packages, Habitat also allows you to export your hart packages into other formats. By far the most popular format people export to is a Docker container image.
Habitat and Containers
Which brings us to Habitat and Containers. Habitat DOES work very well without containers, as we’ve seen, but it shines when we use it WITH containers.
Getting a software package to run anywhere is very difficult. That’s not a new problem, we all know that. And containers were supposed to solve this problem. But there is still a lot of pain with running containers. There is a major learning cliff between development and prod. It’s often very difficult to move from using containers in development to fully using them in production (with the associated monitoring, etc.).
The other major issue is that it is easy for containers to become black boxes – where we deploy them to different environments without fully understanding everything that is inside of them. Among other things, this can cause serious security issues if a container has something in it with a security flaw, but we don’t know or don’t remember to update it.
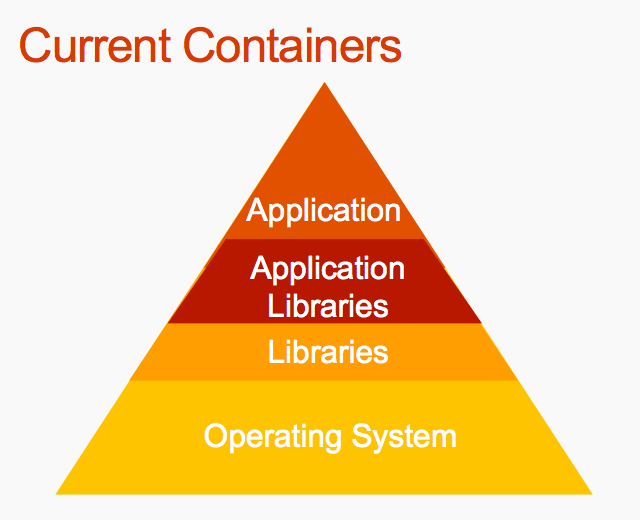
Part of the reason for this is traditional containers start by adding an entire operating system, then adding in the libraries, then the application libraries, and then finally the application itself at the very end. This adds bloat and complexity to containers.

Habitat, by contrast, turns the traditional container workflow on it’s head. You start with the application. Once you have the application, you add in the libraries to run that application, and then only at the end do you add in a bare minimum operating system that is just enough to run your application and nothing more.
When an app has dependencies, the app itself declares those dependencies and resolves them. We don’t add in those dependencies to the container preemptively – the app will pull what it needs and only what it needs.
And, even when that package is within a container, it still has that exposed API we talked about earlier. Other outside services – such as a load balancer – can still interact with the app easily, even though it is in a container.
In summary, when you create a container image with Habitat, you know exactly what went into the container and exactly what is configurable about the container, it’s not a black box.
Now, let’s look at this in action with another video, where we export a built Habitat package as a docker container image, spin up a container with that image, then run that container and view the app inside it in a browser.
Once you have that container image, you can run it locally, but you’re going to want to deploy it somewhere. It doesn’t do much good just sitting on your workstation. You can deploy it using a container scheduling service such as Kubernetes, Mesosphere, and Docker Swarm. You can also use a cloud based container service, like AWS ECS or Azure Container Services. For an example of running a Habiterized container image with AWS ECS, see “Habitat and Amazon Elastic Container Service” by Matt Ray.
Wrap Up
DevSecOps can build software once and run it almost anywhere. You can move a legacy application into the cloud without rewriting it. You can empower your applications to recover from failure on their own. You can do all of these things today with Habitat by Chef.
The key to understanding what Habitat is is to realize that it is not Infrastructure automation, it’s not Container Automation, it’s Application Automation. The application itself is what we are automating.
And Habitat is 100% Open Source. Where it goes from here is going to be driven largely by our community of users and contributors. To get involved, check out our Habitat community site.